宽度优先搜索(Breadth First Search)通常是指图(树也是图)的一种查找顺序。它从某个节点开始,每次都遍历完当前节点可以直接到达的所有节点,再继续遍历下一层节点,一层一层的搜索。
二叉树的宽度优先搜索
例如我有一个二叉树:
1 | 1 |
我的遍历顺序是1->2->3->4->5->6->7,这就是一种宽度优先搜索。通常树的宽度优先搜索会使用队列来辅助,具体可以看之前的这篇文章二叉树算法 - 广度优先遍历
树的宽度优先遍历通常用来解决
- 深度先关问题
- 需要层级遍历的问题(例如树的序列化和反序列化)
图的宽度优先搜索
图的基本表示方法
我们通常用2种方法来表示图:
- 邻接矩阵(Adjacency Matrix)
- 邻接表(Adjacency List)
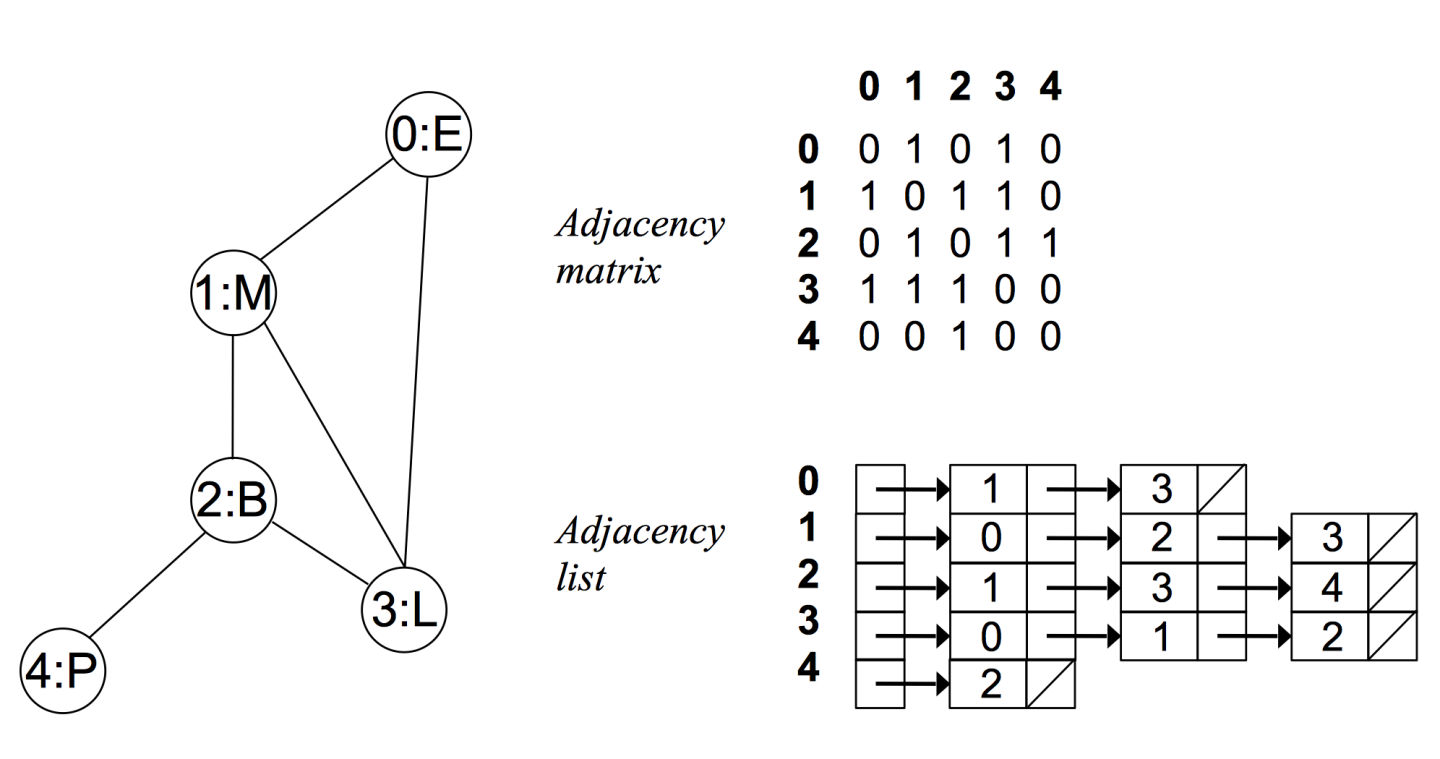
邻接矩阵
通常用二维数组来实现。
- 有 n 个节点的图需要有一个 n × n 大小的矩阵
- 在一个无权图中,矩阵坐标中每个位置值为 1 代表两个点是相连的,0 表示两点是不相连的
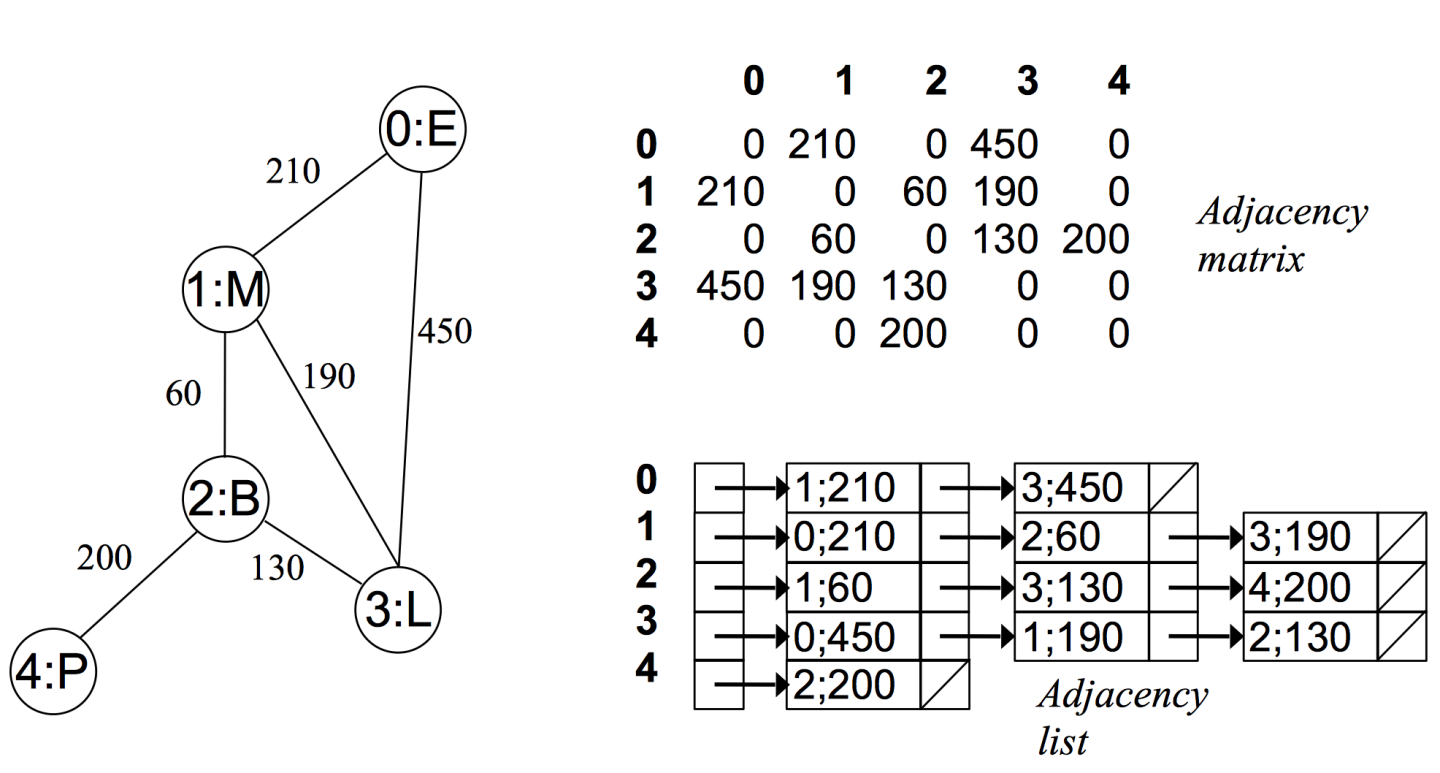
- 在一个有权图中,矩阵坐标中每个位置值代表该两点之间的权重,0 表示该两点不相连
- 在无向图中,邻接矩阵关于对角线相等
邻接表
通常用一维数组+链表来实现。
- 对于每个点,存储着一个链表,用来指向所有与该点直接相连的点
- 对于有权图来说,链表中元素值对应着权重
示例
无向无权图:
无向有权图:
有向无权图: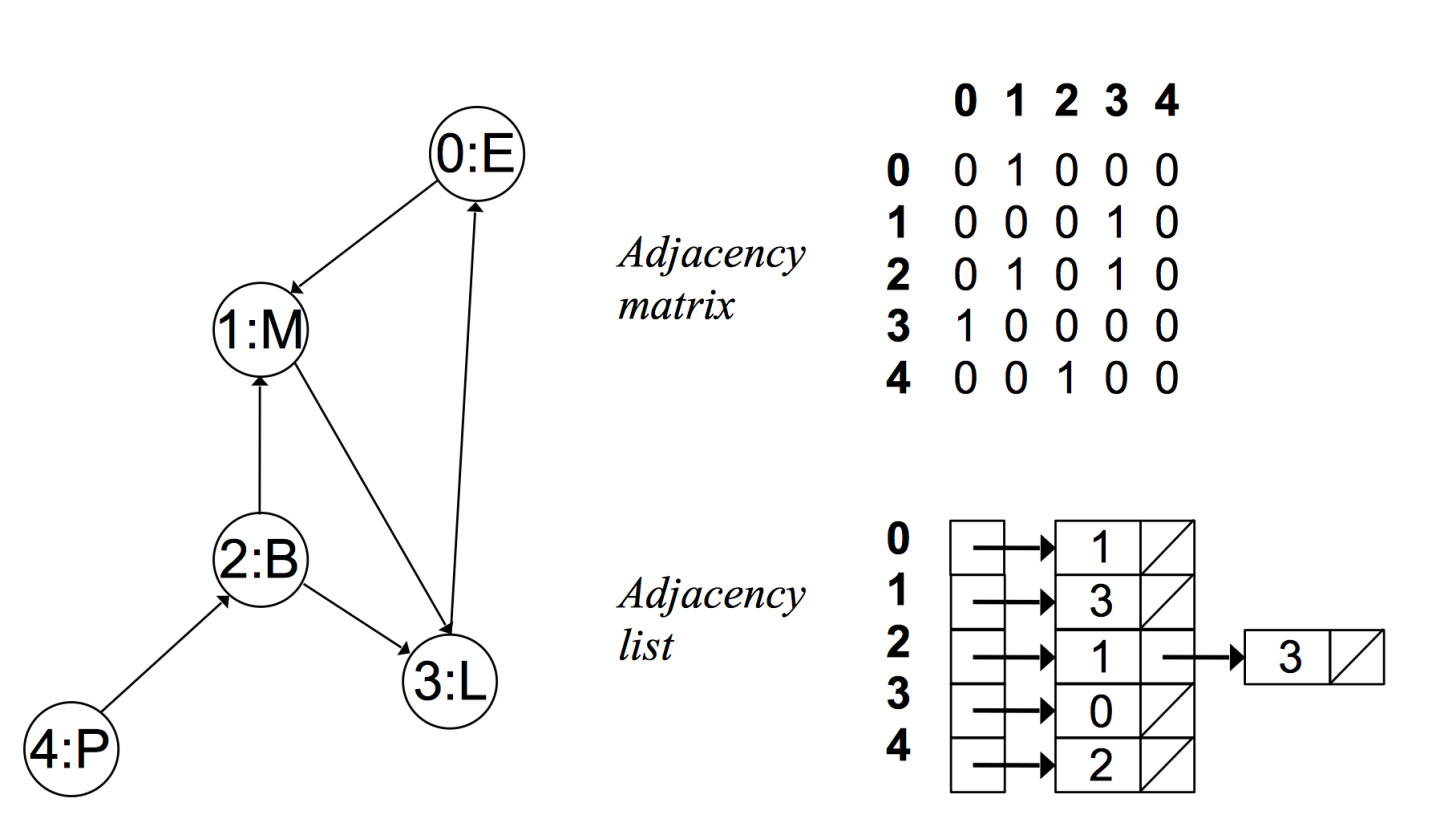
有向有权图:
基于无向有权图改一下就行了。
宽度优先搜索的常见问题
图的搜索算法中,经常会用到宽度优先搜索。例如图的层级遍历、在简单图中寻找最短路径、处理一些由点及面的问题、拓扑排序等,都合适用宽度优先搜索来解决。
- LeetCode 133. Clone Graph
克隆图。可以采用宽搜,对原始图进行层级遍历。
1 | // 这题还有很多其他方法,这里展示宽搜的方法 |
- LeetCode 210. Course Schedule II
课程表。经典拓扑排序问题,可以用宽搜解决。
拓扑排序的通用思路是:
1.找出所有入度为0的节点,放入结果。
2.将这些节点与邻居的边删除,这样它们的邻居的入度就会减少1。
3.重复过程1,直到不能再继续。
这时如果结果的数量与数据集数量一样,说明正常的完成了拓扑排序,否则说明有环,无法完成拓扑排序。
1 | public int[] findOrder(int numCourses, int[][] prerequisites) { |
矩阵宽度优先搜索
涉及矩阵搜索的题目,宽搜也经常应用。此类题目视情况用宽搜或深搜,思路就是把它当成图来处理,只是把图中的节点的表示方法换成了矩阵中的横竖坐标表示。
1 | public int numIslands(char[][] grid) { |
关于“图的基本表示方法”,参考来源: